RX Scanner - 処方箋OCRアプリケーション
Tesseract OCRを活用した医療機関向け処方箋画像認識・薬剤データ管理デスクトップアプリケーション

このプロジェクトはポートフォリオ・技術検証用に開発されました。
実際の医療現場での使用には、追加のセキュリティ対策と機能強化が必要です。
プロジェクト概要
このプロジェクトは、医療機関における処方箋処理業務の効率化を目指して開発したデスクトップアプリケーションです。OCR技術と日本語テキスト処理を組み合わせることで、印刷された処方箋画像から薬剤情報を自動抽出し、レセプトデータとして出力する仕組みを実装しました。
開発の背景として、医療機関での事務作業の多くが手作業に依存しており、特に処方箋のデータ入力は時間がかかる上にヒューマンエラーのリスクも高いという課題がありました。この問題をテクノロジーで解決できないかと考え、画像処理とOCR技術を活用した自動化ツールの開発に挑戦しました。
技術的な挑戦として、単なる機能実装に留まらず、プロダクションレベルの品質を目指しました。CI/CDパイプラインの構築、包括的なテストカバレッジ、クロスプラットフォーム対応、詳細なドキュメント整備まで、実務で求められる開発プロセス全体を経験することを重視しました。Pythonデスクトップアプリケーション開発を通じて、ソフトウェアエンジニアリングの基礎から実践まで幅広く学ぶことができました。
技術仕様
- Language: Python 3.12
- GUI Framework: PySide6 (Qt6 Python bindings)
- OCR Engine: Tesseract OCR (Japanese + English)
- Image Processing: OpenCV
- Database: SQLite + FTS5 full-text search
- Text Matching: rapidfuzz (fuzzy string matching)
- Testing: pytest, mypy, ruff
- CI/CD: GitHub Actions
- Distribution: PyInstaller (Windows/macOS executables)
主な特徴
高精度なOCR処理とパターン認識
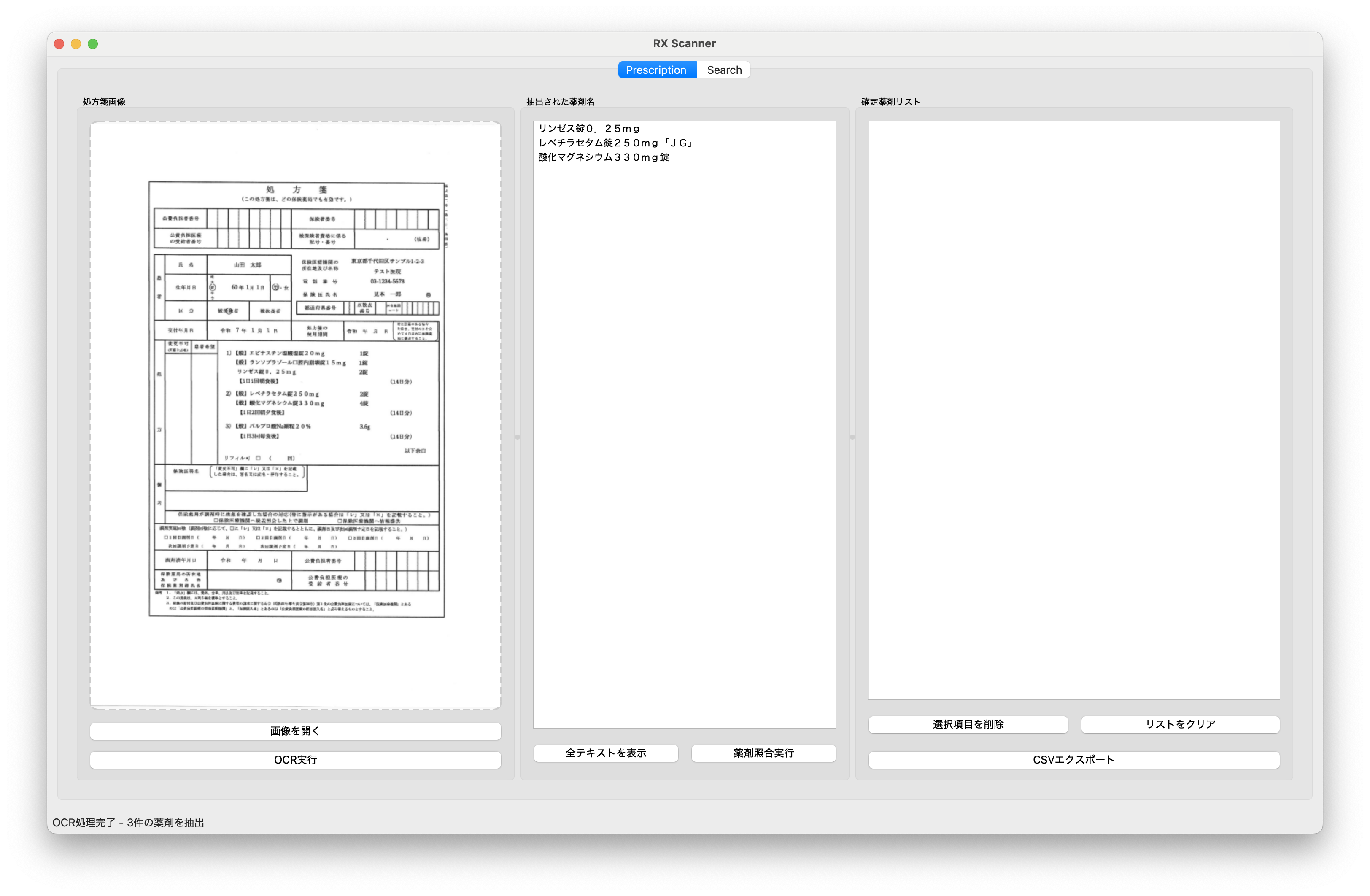
このプロジェクトの核となるのは、Tesseract OCRエンジンを活用した日本語処方箋認識技術です。単純なOCR実装ではなく、医療特有の課題に対応するため、複数の前処理技術を組み合わせました。
画像の前処理では、OpenCVによるノイズ除去、二値化、2倍拡大処理を実施し、OCR精度を大幅に向上させています。印刷された処方箋や低解像度の画像でも安定して認識できるよう、Otsuの二値化アルゴリズムと適応的なデノイジング処理を適用しました。
認識後のテキスト処理では、医療用語特有のパターンに対応した正規表現ベースの薬剤抽出ロジックを実装。29種類の剤形(錠、OD錠、カプセル、散剤など)と規格(mg、g、mL、%など)を自動検出し、構造化されたデータとして抽出します。
さらに、OCR特有の誤認識に対応するため、rapidfuzzライブラリによるファジーマッチングを導入。Levenshtein距離を活用した類似度検索により、「ロキソニン」を「ロキソ=ン」と誤認識した場合でも正しい薬剤にマッチングできる仕組みを構築しました。
4段階信頼度スコアリングシステム
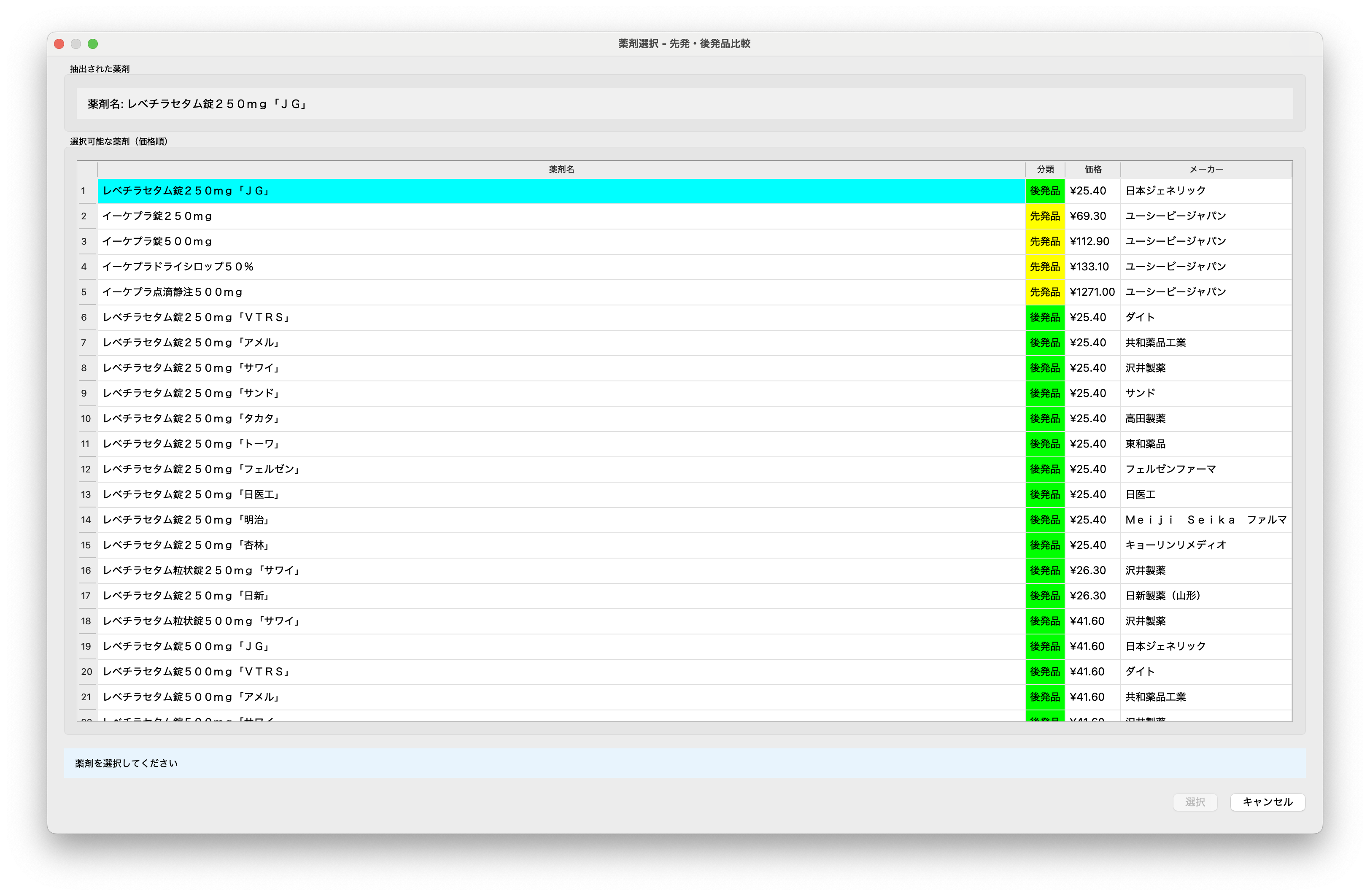
OCR結果の信頼性を定量的に評価するため、独自の4段階信頼度スコアリングシステムを設計・実装しました。このシステムは、データベースマッチングの精度に基づいて0.70〜1.00の範囲でスコアを付与します。
スコアリングロジック
- 1.00 (完全一致):商品名が完全に一致
- 0.90 (剤形・規格一致):剤形と規格が一致
- 0.80 (成分名一致):有効成分名が一致
- 0.70 (部分一致):ファジーマッチングによる類似検索
信頼度が低い(0.80未満)場合、システムは自動的に代替薬剤選択ダイアログを表示し、ユーザーが候補の中から正しい薬剤を選択できるUIを提供します。このダイアログでは、各候補の価格、製造元、規格を比較できるテーブル形式で表示し、情報に基づいた判断をサポートします。
このアプローチにより、完全自動化と人間の判断のバランスを取り、OCRの限界を補いながら実用的な精度を実現しています。
データ管理とCSV出力機能
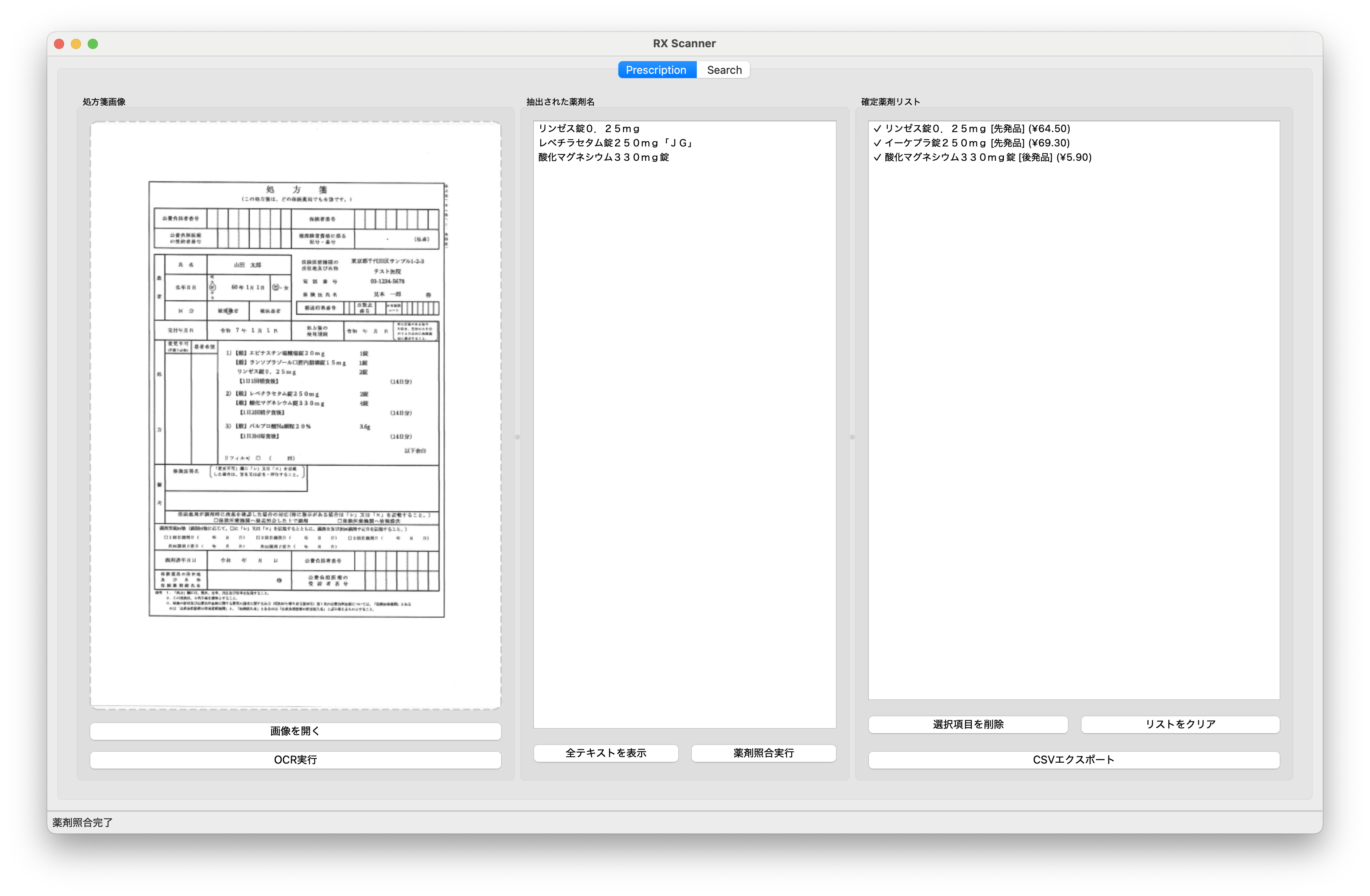
認識した薬剤情報を効率的に管理するため、直感的なUI設計と柔軟なデータ出力機能を実装しました。確定薬剤リストでは、薬剤名、分類、薬価の項目を表示し、追加・削除が可能です。
現在のバージョンでは、用法・用量・日数フィールドは将来の機能拡張用に予約されており、実装の優先順位を考慮して段階的な開発を進めています。まずは薬剤の自動認識とデータベースマッチングというコア機能に注力し、その後の拡張で投薬指示の詳細情報抽出に対応する設計としました。
CSV形式での一括出力機能を搭載し、出力されたCSVファイルは医療事務システムへのインポートや、保険請求データとしての二次利用を想定した構造化フォーマットとなっています。
また、重複薬剤の自動検出機能により、同一成分の薬剤が複数回認識された場合に警告を表示し、データの整合性を保ちます。このような細かいエラー処理の積み重ねが、実務レベルでの信頼性向上に繋がると考え、丁寧に実装しました。
高速全文検索システム
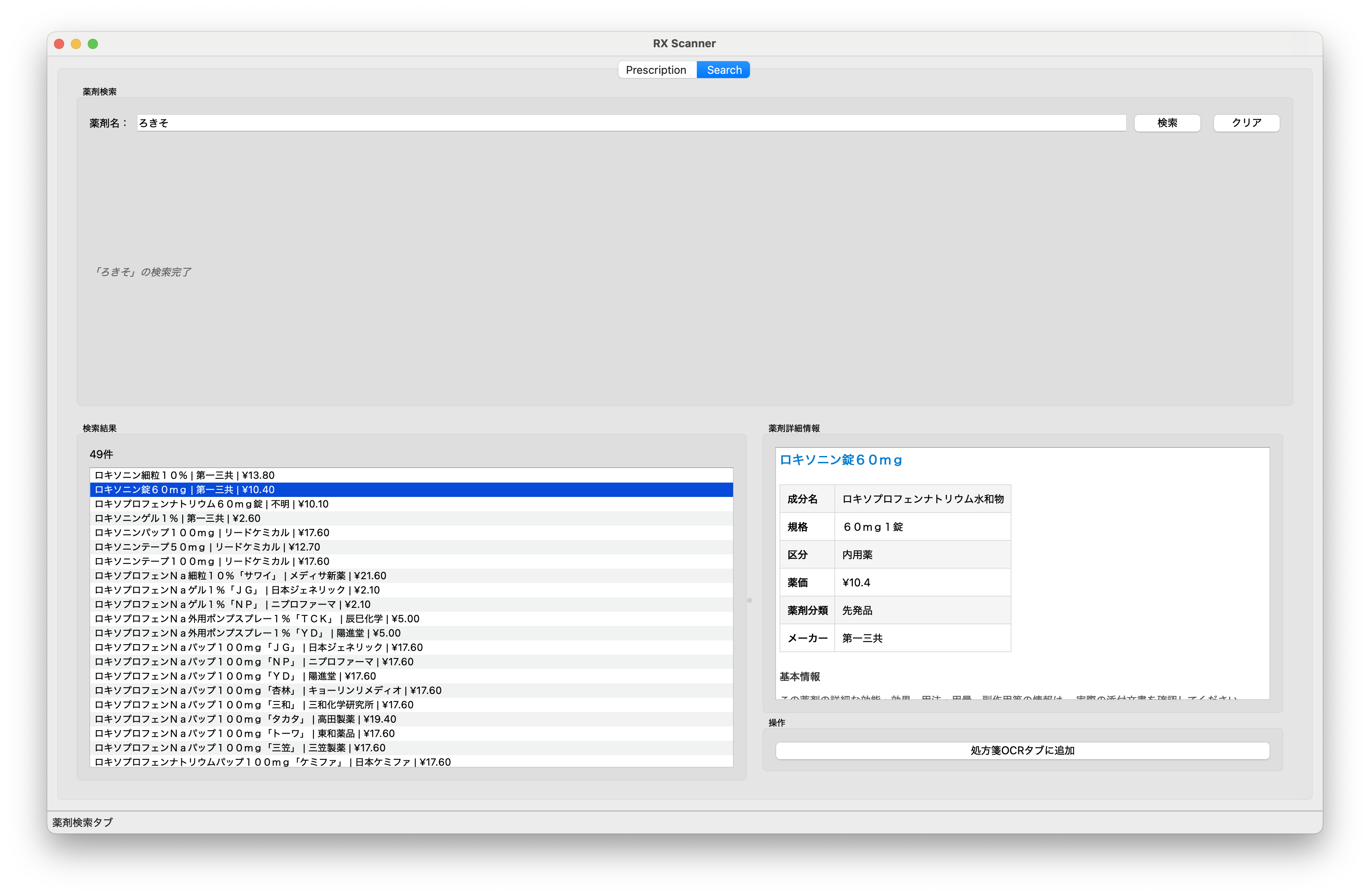
12,445件の薬剤マスタデータから目的の薬剤を瞬時に見つけるため、SQLite FTS5(Full-Text Search)エンジンを活用した高速検索システムを構築しました。
日本語検索の課題として、ひらがな・カタカナ・漢字が混在する医薬品名の正規化処理が挙げられます。これに対応するため、すべての検索クエリとデータベース内容をカタカナに正規化する前処理パイプラインを実装。「ろきそにん」「ロキソニン」「ろキソニン」のいずれの入力でも同一の結果を返せるようにしました。
検索UIでは、500msのデバウンス処理によるインクリメンタルサーチを実装し、タイピング中でもスムーズに結果が更新される体験を提供。2文字以上の入力で検索を開始し、結果件数を表示することでユーザーに適切なフィードバックを返します。
検索結果をクリックすると詳細情報パネルが表示され、薬価、製造元、規格などの情報を確認した上で、ワンクリックで処方箋タブの確定リストに追加できる統合設計を実現しています。
エンジニアリングプラクティス
CI/CDパイプライン
GitHub Actionsを活用した自動化されたテスト・ビルド・デプロイパイプラインを構築しました。
継続的インテグレーション (CI):
- プルリクエストごとに自動テスト実行
- Windows/macOSでのクロスプラットフォームテスト
- コード品質チェック(ruff、mypy)
- コードカバレッジ測定(Codecov統合)
継続的デプロイメント (CD):
- バージョンタグ作成時に自動リリース
- Windows/macOS向け実行ファイル自動生成
- データベース自動バンドル
- GitHubリリースページへの自動アップロード
このCI/CDパイプラインにより、コードの品質を保ちながら迅速なリリースサイクルを実現しています。
テスト駆動開発
信頼性の高いアプリケーションを目指し、pytestを使った包括的なテストスイートを構築しました。
テストカバレッジ:
- データベース操作(16テスト)
- OCR処理・薬剤マッチング(30+テスト)
- CSVインポート(17テスト)
- エッジケース・エラーハンドリング
特に、OCRの信頼度スコアリングロジックやファジーマッチングアルゴリズムなど、複雑なビジネスロジックについては徹底的にテストケースを作成し、リファクタリング時の安全性を確保しました。
クロスプラットフォーム対応
Windows・macOS両環境での動作を保証するため、プラットフォーム固有の課題に個別対応しました。
Windows対応:
- UTF-8エンコーディングの明示的設定
- PowerShell互換のビルドスクリプト
- charmap codec問題の解決
macOS対応:
- Gatekeeper警告への対策(実行手順の簡略化)
- Homebrewパス検出ロジック
- Qt on macOSの既知問題への対処
PyInstallerによる実行ファイル生成では、データベースファイルや依存ライブラリを自動バンドルし、ダウンロード後すぐに使えるユーザー体験を実現しました。
主な機能
コア機能
- ✅ 処方箋画像のドラッグ&ドロップアップロード
- ✅ マルチスレッドOCR処理(進捗表示付き)
- ✅ 4段階信頼度スコアリング
- ✅ 代替薬剤選択ダイアログ
- ✅ 確定薬剤リスト管理
- ✅ CSV形式レセプトデータ出力
データベース機能
- ✅ 12,445件の薬剤マスタデータ
- ✅ FTS5全文検索
- ✅ 日本語正規化(ひらがな・カタカナ統一)
- ✅ インクリメンタルサーチ
開発・運用
- ✅ GitHub Actions CI/CD
- ✅ クロスプラットフォームテスト
- ✅ コードカバレッジ追跡
- ✅ 自動リリースワークフロー
- ✅ Windows/macOS実行ファイル配布
技術的チャレンジと学び
1. OCR精度向上の試行錯誤
OCRの精度を向上させるため、様々な前処理パラメータの調整を繰り返しました。特に、画像の拡大率、ノイズ除去の強度、二値化の閾値といったパラメータが認識率に大きく影響することを学び、最適なバランスを見つけるプロセスを通じて、画像処理の奥深さを実感しました。
2. 日本語テキスト処理の複雑さ
医薬品名の表記揺れ(ひらがな・カタカナ・漢字の混在)への対応は予想以上に複雑でした。単純な文字列マッチングではなく、正規化処理とファジーマッチングを組み合わせる必要があり、日本語テキスト処理の難しさと重要性を学びました。
3. クロスプラットフォーム開発の課題
Windows・macOSの両環境で安定動作させるため、文字エンコーディング、ファイルパス、OSごとのAPI差異など、数多くの互換性問題に直面しました。これらを一つずつ解決していくプロセスを通じて、クロスプラットフォーム開発の重要性と難しさを実感しました。
4. CI/CDパイプラインの価値
GitHub Actionsによる自動テスト・ビルド・デプロイの仕組みを構築したことで、コード変更の影響範囲を即座に把握でき、安心してリファクタリングできる環境が整いました。手動テストの負荷が大幅に軽減され、開発速度が向上したことを実感しています。
まとめ
RX Scannerプロジェクトは、OCR技術とテキスト処理を組み合わせた実用的なアプリケーション開発を通じて、ソフトウェアエンジニアリングの包括的なスキルを習得する機会となりました。
技術的には、画像処理からデータベース設計、UI/UX設計、テスト自動化、CI/CDパイプライン構築まで、現代的なソフトウェア開発で求められる幅広い技術領域を経験できました。特に、単に動くコードを書くだけでなく、保守性・拡張性・信頼性を意識したコード設計の重要性を深く理解しました。
また、実際の業務課題を想定した開発を行うことで、技術選定の理由付け、エラーハンドリングの重要性、ユーザビリティへの配慮など、プロダクション環境を意識した開発プロセスを学ぶことができました。
今後は、このプロジェクトで培った経験を活かし、より大規模で複雑なシステム開発に挑戦していきたいと考えています。